


 187
187
从早期的邮政编码识别到如今无处不在的文字提取,光学字符识别(Optical Character Recognition,OCR)有着广泛的应用。OCR分文本检测和文本识别两个步骤,即首先定位文本,然后再进行识别。
在工业图像处理领域,OCR有其自身的一些特点:
(1) 字符以印刷体为主,一致性好。
(2) 需要识别的字符数量较少,比如产品的序列号之类的。
(3) 所能提供的标准字符图像不多,有时甚至只有一幅图像。
(4) 文本位置固定。
(5) 用于字符识别的计算机配置一般。
近年来,以深度学习为代表的算法在OCR应用中取得了惊人的成就,各种环境下的字符识别率极高。但深度学习算法需要大量训练数据以及高性能计算机,因此并不适合大多数工业OCR场景。另外,由于工业OCR中的文本位置固定,因此我们不讨论文本检测算法,感兴趣的读者可以参考[Tian, 2016],文中提出了一种名为CTPN(Connectionist Text Proposal Network)的文本检测模型,文本定位效果很好。
在只有很少标准字符图像,并且识别的字符不多的情况下,用图像匹配算法即可。除此之外,大部分工业OCR应用可采用贝叶斯分类器、SVM等算法。本文讨论的内容包括应用传统图像处理技术对字符进行分割、提取特征以及用贝叶斯分类器对字符进行分类。
字符分割
用贝叶斯分类器等机器学习算法进行字符识别的第一步就是将文本分割成单个字符。在字符分割前,对于图1和图2这类图像,需要通过投影变换和极坐标变换将文本变换成矩形排列。对于大部分字符分割,采用分割技术已经足够了,但是对于粘连字符需要采用针对性技术。如图3所示,图3(a)是MingLiU-ExtB字体的文本,两个字符呈粘连状态。对于这类的粘连字符,首选的方案就是用开或闭运算对其进行分割,这里采用3×11结构元进行闭运算(前景为白色),结果如图3(b)所示。之所以采用细长结构元,是为了防止在分割时造成字符在水平方向断开。此外,我们还可以将二维图像的像素灰度值投影到一维的水平轴上,即行剖面,然后根据波峰或波谷确定粘连位置。图3(c)为图3(a)行剖面,可以看到,在水平坐标126附近有一波峰,对应的就是粘连位置。

图1.投影变换应用

图2.CD 和极坐标变换的结果
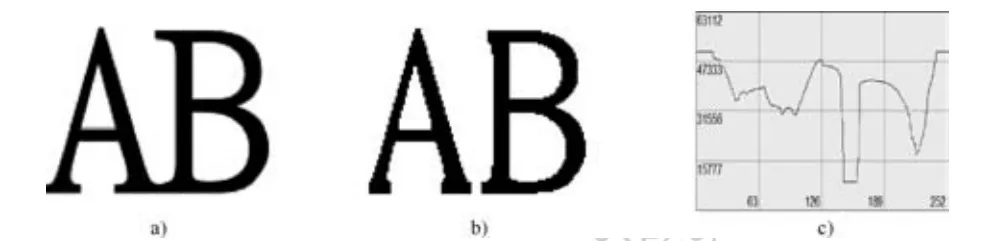
图3.MingLiU-ExtB字体的文本(尺寸252×198像素) (b)用3×11结构元对二值化后的图a进行闭运算的结果;(c)图a的行剖面
但是,上述的形态学方法并不总有效。如图4所示,图4(a)为字符粘连的图像,图4(b)是对二值化后的图4(a)进行开运算的结果,由于图4(a)与图3(a)的前景相反,所以用了相反的形态学算法。从图中可以看到,除了“C”和“8”,“1”和“A”外,其他粘连字符并未分开。对于这类重度粘连的字符,如果是等宽字符,可以在确定了首字符的位置后,根据字符宽度进行分割。对于非等宽字符,如果不同宽度字符出现的位置是确定的,也可以根据字符宽度进行分割。

图4.(a)字符粘连的图像;(b)用5×9结构元对二值化后的图(a)进行开运算的结果
另外,对于诸如“i”、“j”或点阵之类的字符,在分割前需要进行膨胀或腐蚀处理,以使单个字符连接到一起。如图5所示,图5(a)是产品包装上常见的点阵字符串,图5(b)是对图5(a)二值化后再腐蚀的结果。经过这样的处理,单个字符都连接起来了,不会出现一个字符分割成几部分的情况。
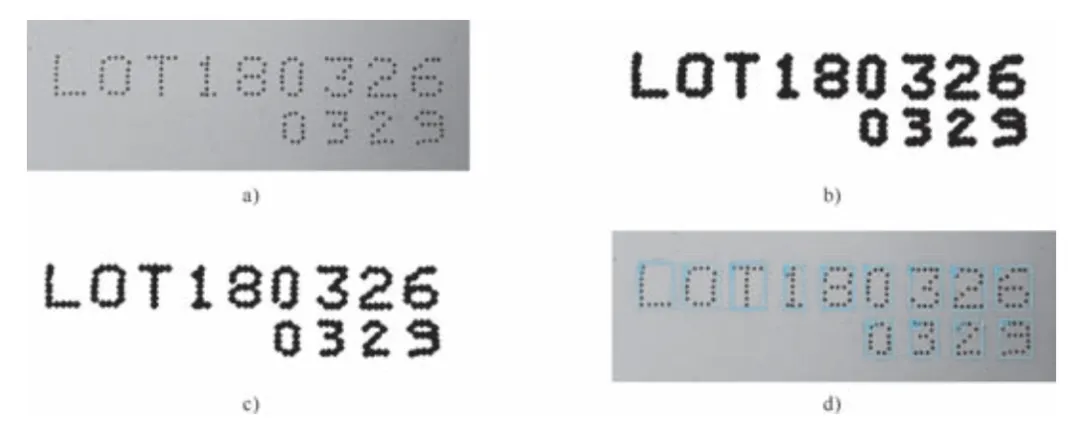
图5.(a)点阵字符;(b)对图(a)二值化后腐蚀的结果(结构元9×9);(c)对图(b)膨胀的结果(结构元3×3);(d)图(a)叠加图(c)的区域分析结果
对字符分割完毕后,需要通过区域分析,在图像上确定包含字符的外框。一般来说,我们希望外框与字符之间有一两个像素的间隙。我们以图5为例对此进行讨论。由于进行了腐蚀运算,如果直接提取图5(b)中的字符的外框,尺寸会过大。所以首先对图5(b)进行膨胀运算,如图5(c)所示。然后再提取外框,叠加到原图后的效果如图5(d)所示,外框与字符之间有一定的间隙。如果分割中没有进行形态学操作,可以在提取外框前做一次3×3的腐蚀运算(假设字符为黑色),以保证字符与外框之间有一个像素的间隙。
特征提取
字符分割完毕后,接下来就是特征提取。可以将多种图像信息作为样本的特征:灰度值、梯度、二值图像、行剖面、列剖面、高宽比、高度、宽度等,其中高宽比等为单一特征,一般与灰度值等组合使用,以提高对字符的分辨能力。
如图6所示,图6(a)是分割出来的字符。如图直接用图6(a)的像素灰度值序列作为特征,则样本的维数为36×45=1620,维数过高,需要降维。此外,分割出来的字符尺寸不一,造成样本维数不同。因此,提取特征之前需要对字符进行缩放,对于工业应用来说,将字符缩放到8×10比较恰当[Steger, 2019]。如果在应用中只有很少的字符类型,比如只有数字,则可以使用更小一点的尺寸;如果包含较多的字符类型,比如数字、大写字母和小写字母,则可使用更大的尺寸,比如10×12。将图6(a)缩放8×10后,如图6(b)所示,这时样本维数为80。缩放建议采用双线性插值法,可以同时兼顾效率和质量。

图6.提取灰度值特征
(a)深色字符“9”(尺寸36×45);(b)将图(a)缩放到8×10;(c)对图(a)归一化后再缩放到8×10(去掉直方图两端5%的像素后的灰度值作为归一化最值。归一化后的浮点数图像映射到[0, 255]);(d)浅色字符“9”;(e)将图(d)缩放到8×10;(f)对图(d)归一化后再缩放到8×10
但是这样直接缩放是有问题的。图6(d)是光照发生变化的字符“9”图像,图像亮度更高,缩放到8×10后的图像如图6(e)所示。图6(b)与图6(e)灰度值差异较大,这样会造成后续的分类很困难。解决这个问题的方法就是在缩放前对灰度值进行归一化处理。归一化可以理解为一种灰度拉伸,是将图像的动态范围[r1,r2]映射到[0,1],即
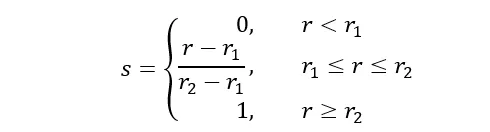
公式1
式中,s为输出灰度值,r为输入灰度值。为了降低噪声的影响,我们不建议r1和r2取图像的灰度最小值和最大值,而是取去掉直方图两端一定比例的像素后的灰度最值。灰度值归一化后再缩放到8×10的字符如图6(c)和6(f)所示,这时二者的灰度值基本一致。
由于我们是将分割得到的包含字符外接矩形的图像缩放到一个标准尺寸,那么对于有些字体中的个别字符,比如等线字体中的“I”和“-”,就不能分辨开,因为缩放后的图像是一样的。解决这个问题的方法就是额外增加一个特征,将分割得到的字符外接矩形的高宽比作为一个特征。这样,对于8×10的字符来说,样本维数就是81。
由于梯度对光照变化不敏感,因此梯度也是一种常用的特征。与构造SIFT关键点描述符类似,首先将图像缩放到一个标准尺寸,例如35×35,然后再将图像细分为5×5个子区域,每个子区域尺寸为7×7。最后计算每个像素点的梯度并离散到间隔45°的8个方向,共构成200个梯度特征[Liu, 2004][Steger, 2019]。
字符分类
我们使用正态贝叶斯分类器作为OCR分类器。在对字符分割以及特征提取后就得到了样本集,用分类器进行训练和测试即可。下面通过一个例子来讲述OCR的完整过程。
例.用正态贝叶斯分类器进行OCR及异常检测
如图7示,图7(a)是包含训练字符的原图,数字0~9,共10行,每行20个字符。图7(b)是用自动阈值对图7(a)分割后再腐蚀的结果。图7(c)是区域分析后得到的包含字符的矩形框。提取每个字符的特征并生成样本后,还需要标记每个样本。如果矩形框的排列顺序未知,那么可以用细长结构元对图7(b)进行腐蚀,结果如图7(d)所示,通过区域分析得到包含每行字符的矩形框。对于图7(c)中那些矩形框中心落入图7(d)同一矩形框内的字符做相同的标记。对样本标记后,就可用分类器进行训练了。

图7.字符分割及特征提取
(a)包含训练字符的原图(尺寸871×730像素);(b)对图(a)二值化后再腐蚀(自动阈值,5×5八边形结构元);(c)对图(b)区域分析后得到的包含字符的矩形框;(d)用35×1矩形结构元对图(b)腐蚀后再区域分析
训练完毕后即可进行字符分类。如图8所示,图8(a)是包含待识别字符的原图,其中有未训练字符“M”。如果直接分类,结果如图8(b)所示,“M”识别成了“7”。现在我们观察用式1计算的各字符的f(kk)的值,如表1所示。可以发现,“M”的值f(kk)要明显小于其他字符,因此我们用阈值,比如-26,进行异常检测,结果如图8(c)所示,“?”表示异常字符。

图8.用正态贝叶斯分类器进行字符识别
(a)包含待识别字符的原图;(b)不进行异常检测的识别结果;(c)进行异常检测的识别结果

表1.字符f(kk)值
以上内容节选自《图像处理与机器学习:算法深度解析与应用实践》






