


 370
370
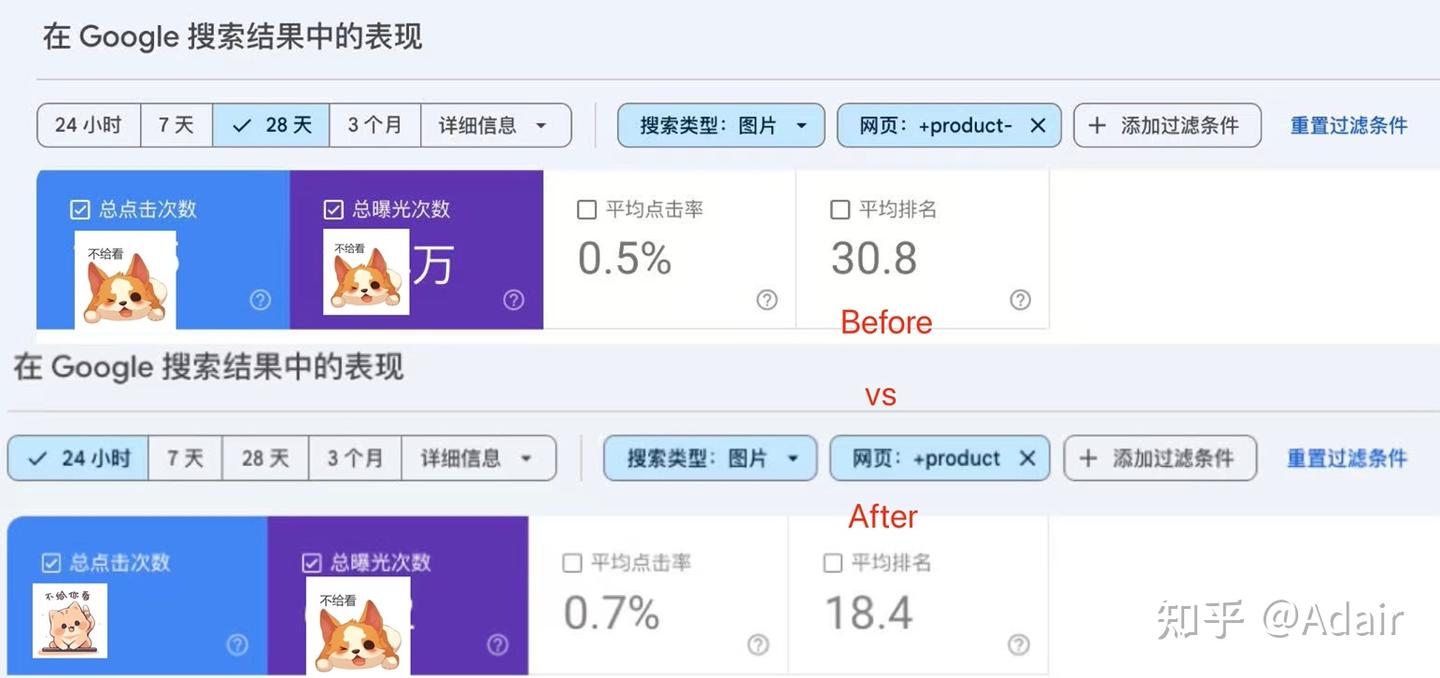
?ČçşÎŔűÓĂx86µĄ°ĺ»úLattePanda SigmaŁ¨x86 SBC/µĄ°ĺ»úŁ©+Intel ˝áşĎÓëĘÓľőÄŁĐÍŁ¬˝«18000˛úƷͼƬÖĐʵĎÖaltÎıľ×Ô¶ŻÉúłÉÓëSEOÓĹ»ŻˇŁ´Ó¶řĚáÉýÍřŐľSEO±íĎÖµÄŐćʵӦÓĂ°¸ŔýˇŁ·ÖĎíÁËĽĽĘőÔŔíˇ˘ĘµĘ©˛˝Ö衢AB˛âĘÔ·˝·¨ˇ˘ĐÔÄÜĘýľÝşÍłŁĽűÎĘĚ⣬°ďÖúĆóҵŔí˝â»ůÓÚµĄ°ĺ»úµÄAI±ßÔµĽĆËăÔÚSEOÖеļŰÖµˇŁĆ˝ľůµă»÷ÂĘ´Ó0.5%Ěá¸ßµÄ0.7%ˇ˘Ć˝ľůĹĹĂű´Ó30.8 Ěá¸ßµ˝18.4ˇŁŐâŔďĂćÎŇĂÇÓжÔͼƬĚíĽÓÁË
±łľ°
ÎŇÔÚ·ÖÎöÍřվʱ·˘ĎÖÁËŇ»¸öľŢ´óµÄÎĘĚ⣺ÎŇĂÇ´óÔĽÓĐ3000¸ö˛úĆ·ŇłĂ棬ÿ¸ö˛úĆ·´óÔĽÓĐ6ŐĹͼƬŁ¬×ܼƽӽü18000ŐĹÍĽĎńŁ¬ĆäÖĐ95%ŇÔÉĎĂ»ÓĐÉčÖĂaltĘôĐÔˇŁČËą¤˛ąĆë 18 k Ěő Alt °´ 60 s/ŐĹĐč 300 ČËʱŁ¬łÉ±ľ 2.4 w ÔŞˇŁÓÚĘÇÎŇ°ŃÄżąâͶĎňˇ°±ßÔµ AIˇ±ˇŞˇŞČõĄ°ĺ»ú×ÔĽşˇ°ż´ˇ±×ÔĽşˇ°Đ´ˇ±ˇŁ
ʲôĘÇͼƬaltĘôĐÔŁ¬ÎŞĘ˛Ă´¶ÔSEOČç´ËÖŘŇŞŁż
ͼƬaltÎıľŁ¨alternative textŁ©ĘÇHTML±ęÇ© µÄĂčĘöĐÔÎÄ×ÖŁ¬ËüµÄ×÷Óò»˝ö˝öĘǸ¨ÖúĘÓľőŐĎ°ÓĂ»§Ŕí˝âÍĽĎńÄÚČÝŁ¬¸üĘÇËŃË÷ŇýÇćÓĹ»ŻŁ¨SEOŁ©ÖеĹؼüŇňËءŁ
ËŃË÷ŇýÇ汾ÉíÎŢ·¨ĎńČËŔŕŇ»Ńůˇ°ż´¶®ˇ±ÍĽĎńŁ¬Ňň´ËËü»áŇŔŔµaltĘôĐÔŔ´Ŕí˝âͼƬµÄÄÚČݡ˘łˇľ°ÓëĎŕąŘĐÔˇŁČçąűȱÉŮaltĘôĐÔŁş
ͼƬÎŢ·¨łöĎÖÔÚGoogleͼƬˇ˘BingͼƬµČËŃË÷˝áąűÖСŁ
ŇłĂćĎŕąŘĐÔ˝µµÍŁ¬ł¤Î˛ąŘĽü´Ę¸˛¸Ç¶Č˛»×㡣
ÎŢŐĎ°ĚĺŃéĎ½µŁ¬ÓĂ»§ĚĺŃ鲻ĽŃˇŁ
ÔÚµçÉĚÍřŐľÖĐŁ¬Őâ¸öÎĘĚâÓČĆäŃĎÖءŁĂż¸ö˛úĆ·¶ĽÓжŕŐĹͼƬŁ¬ČçąűaltÎıľČ±Ę§Ł¬ľÍµČÓڶ޵ôÁ˾޴óµÄł¤Î˛Á÷Áż»ú»áˇŁ
ΪʲôѡÔńLattePanda SigmaŁż
LattePanda SigmaĘÇŇ»żî»ůÓÚx86ĽÜąąµÄ¸ßĐÔÄܵĄ°ĺ»úŁ¨x86 SBCŁ©Ł¬Ďŕ±ČARMĽÜąąµÄĘ÷Ý®Ĺɡ˘RISC-VżŞ·˘°ĺŁ¬Ëü×î´óµÄÓĹĘĆÔÚÓÚŁş
ÍęŐűµÄx86Éú̬ŁşÄÜÔÉúÔËĐĐWindowsşÍLinuxŁ¬ĽćČÝÖ÷Á÷AIżňĽÜÓ뿪·˘ą¤ľßˇŁ
ĐÔÄܸüÇżŁşĘĘşĎÔËĐĐollamaŐâŃůµÄ±ľµŘ´óÓďŃÔÄŁĐÍŁ¨LLMŁ©ÓëĘÓľőÄŁĐ͡Ł
±ßÔµĽĆËăÓѺãşÖ±˝ÓÔÚ±ľµŘ´¦ŔíŁ¬˛»ŇŔŔµÔƶˣ¬˝µµÍŃӳٺʹřżíĎűşÄˇŁ
ÎŇŐýĘÇŔűÓĂLattePanda SigmaŁ¬°ŃAIÄŁĐͲżĘđÔÚ±ßÔµ˛ŕŁ¬ĘµĎÖÁË´óąćģͼƬaltĘôĐÔµÄ×Ô¶ŻÉúłÉˇŁ
ĽĽĘőĽÜąąÓëÔŔí
ÄŁĐÍѡÔńŁş + Ë«ĘÓľőÄŁĐÍ+ÎÄÉúÎÄ AB˛âĘÔ
ÔÚʵĽůÖĐŁ¬ÎŇѡÔńÁËollamaŔ´ÔËĐĐÁ˝¸ö˛»Í¬µÄÄŁĐÍŁş
mini-cpm-vŁ¨ĘÓľőÄŁĐÍŁ©ŁşÉĂł¤´ÓÍĽĎńÖĐĚáȡÎÄ×ÖÓëÓďŇĺĐĹϢˇŁ
qwen2.5vlŁ¨ĘÓľőÄŁĐÍŁ©ŁşÉĂł¤´ÓÍĽĎńÖĐĚáȡÎÄ×ÖÓëÓďŇĺĐĹϢˇŁ±Č˝ĎÄÜŔí˝âĚáĘľ´ĘŁ¬ÉúłÉÄÚČݱȽ϶̡Ł
 ?
?ͨąý¶Ô±Č˛»Í¬ÉúłÉ·˝Ę˝µÄaltÎıľÖĘÁżŁ¬ÎŇĂÇÄÜłÖĐřÓĹ»ŻÄŁĐÍĚáĘľ´ĘşÍÉúłÉÂ߼ˇŁ
ĘýľÝ´¦ŔíÓëČÎÎńµ÷¶Č
Őű¸öÁ÷łĚÓÉÁ˝¸ö˛ż·Ö×éłÉŁş
ÍĽÉúÎÄŁ¨Vision-to-TextŁ©ŁşPython ˝Ĺ±ľµ÷ÓĂollama˝ÓżÚŁ¬ÔËĐĐÔÚsigmaşÍIntel»úĆ÷ÉĎŁ¬¸şÔđĹúÁż˝âÎö˛úƷͼƬˇŁ
ÎÄÉúÎÄŁ¨Text-to-TextŁ©ŁşÔÚʵĽů˛âĘÔąýłĚÖĐ·˘ĎÖĘÓľőÄŁĐÍËĽżĽÄÜÁ¦˝ĎČőŁ¬˝«ÍĽĎń˝áąűÓë±ęĚ⡢˛úĆ·ąŘĽü´Ę˝áşĎŁ¬ÔŮͨąýLLM Ł¨ËĽżĽÄŁĐÍŁ©ÓĹ»ŻaltĂčĘöˇŁĘµĎÖollama + ĘÓľőÄŁĐÍ + ÎÄÉúÎÄČýĽ¶Á÷Ë®Ďß
¶¨Ę±ČÎÎńŁşÎŇÓĂGolangĐ´ÁËŇ»¸ö¶¨Ę±ČÎÎńŁ¬±ŕŇëłÉ.exeŁ¬Ö±˝ÓÔËĐĐÔÚLattePanda SigmaÉĎŁ¬ĂżĚě×Ô¶ŻĹúÁżÉúłÉşÍ¸üĐÂaltĘôĐÔˇŁ
Golang ¶¨Ę±ČÎÎń.exe ©¤©Đ©¤ Ăż5·ÖÖÓµ÷ÓĂŇ»´ÎŁ¬˛éŃŻĂ»ÓĐaltĘôĐÔµÄͼƬµŘÖ·
©Ŕ©¤ Python pipeline.py
©¦ ©Ŕ©¤ A ×飺µ÷ÓĂ ollama mini-cpm-v ©¬©´
©¦ ©¸©¤ B ×飺µ÷ÓĂ ollama qwen2.5-vl ©¬©Ľ
©¦ ©¸©¤ şĎ˛˘şňѡÎÄ°¸
©Ŕ©¤ Prompt Engineer ¶ţ´ÎÉúłÉ
©¦ ©¸©¤ ˝áşĎ±ęĚâ+ąŘĽü´Ę+ŔŕÄżµČŁ¬×ß qwen3 ÎÄÉúÎÄ AB ˛âĘÔ
©¸©¤ »ŘĐ´ MySQLŁ¬±ęĽÇˇ°ŇŃÉúłÉˇ±Í¨ąý¶Ô˛úĆ·ľŔíˇ˘ÔËÓŞµČÓĂ»§ÎĘľíµ÷˛éŁ¬2¸öÄŁĐ͵÷Ö2:2Ł¬ĎßÉĎľö¶¨˛ÉÓĂÁËAB˛âĘԵķ˝Ę˝ˇŁ
 ?
?ŐâŃůŁ¬Őű¸öÍřվÿĚ춼ÄÜÓĐĘý°ŮŐĹͼƬ»ńµĂеÄSEOÓŃşĂĂčĘöˇŁ
ľŃé×Ü˝á
ĘÓľőÄŁĐͲ˘·ÇÍňÄÜŁşĘÓľőÄŁĐÍÖ»¸řˇ°ŃŰľ¦ˇ±Ł¬ÎÄ°¸ÖĘÁżżżˇ°ÎÄÉúÎġ±¶ţ´Î°ŃąŘŁ¬EEAT µĂ·Ö¸ü¸ßˇŁ
ĚáĘľ´Ęą¤łĚÖÁąŘÖŘŇŞŁşÔÚÎÄÉúÎÄÓĹ»ŻĘ±Ł¬ÎŇÉčĽĆÁ˽ṹ»ŻĚáĘľ´ĘŁ¬ŔýČç {˛úĆ·Ăű} + {şËĐĹؼü´Ę} + {ͼƬ˝Ç¶Č}Ł¬Ľ«´óĚáÉýÁËÉúłÉÎıľµÄSEOÖĘÁżˇŁ
±ßÔµĽĆËăČĂŇ»Çиü¸ßЧŁşÖ±˝ÓÔÚLattePanda SigmaÉĎÔËĐĐŁ¬±ÜĂâÁËÔƶ˷ŃÓĂÓëŃÓłŮÎĘĚ⣬˛żĘđÓëÔËά¸üÁé»îˇŁ
łŁĽűŇÉÎĘ FAQ
Q1: Ϊʲô˛»ÓĂÔĆ¶Ë APIŁż
A: ĘÔąý,ÂňµÄĚÚѶ»ěÔŞ´óÄŁĐ͡Ł·ŃÓĂ»ąĘDZȽϸߣ¬ÉęÇë·ŃÓúͲâĘÔ¶Ľ˛»Ě«ĘʺϡŁ·ĹĆúˇŁÔÚµĄ°ĺ»ú»ňµçÄÔ±ľµŘĹÜÁăÁ÷Áż·ŃŁ¬Ëć±ăł˘ĘÔ ĘÓƵתÎÄ×ÖҲżÉŇÔˇŁ
Q2: altÎıľ»á˛»»áÉúłÉÖظ´Łż A2: ÎŇÔÚPython˝Ĺ±ľÖĐĽÓČëÁËČĄÖŘÂ߼Ł¬˛˘˝áşĎ±ęĚ⡢ąŘĽü´ĘŁ¬±ŁÖ¤ĂżŐĹÍĽµÄaltĂčĘöľˇżÉÄÜΨһˇŁ
Q3: mini-cpm-vÓëqwen2.5vl˸üşĂŁż A3: mini-cpm-vÔÚOCRşÍÍĽĎńĂčĘöÉϸüÎČŁ¬µ«qwen2.5vl˝áşĎÎÄÉúÎÄÓĹ»ŻşóŁ¬ÄÜÉúłÉ¸ü·űşĎSEOĐčÇóµÄł¤Î˛ĂčĘöˇŁAB˛âĘÔżÉŇÔ°ďÖúłÖĐř¸Ä˝řˇŁ
Q4: LattePanda SigmaĹÜŐâĐ©ÄŁĐͻ᲻»áąýČČŁż A4: ʵ˛âÖĐĿǰһÇĐŐýłŁŁ¬Í¨ąý·çÉČɢČČĽ´żÉÎȶ¨ÔËĐĐŁ¬˛»»áÓ°Ď춨ʱČÎÎńˇŁ
?


